Website styling update
After making this blog back in December 2024, I already knew that I'd not be satisfied by the way it looks for long.
At the end of July 2025, a new "stealth"/"cloaked" model appeared as Horizon Alpha and later Horizon Beta on openrouter.ai, and my timeline on X/Twitter got quite excited about its frontend capabilities.
I decided to use it to initiate a few small design changes, and these models turned out to be early checkpoints of GPT5.
Introduction
Unfortunately, I did not take many screenshots in the process (only one, in fact 💀), but here's a visual TL;DR:
Before:
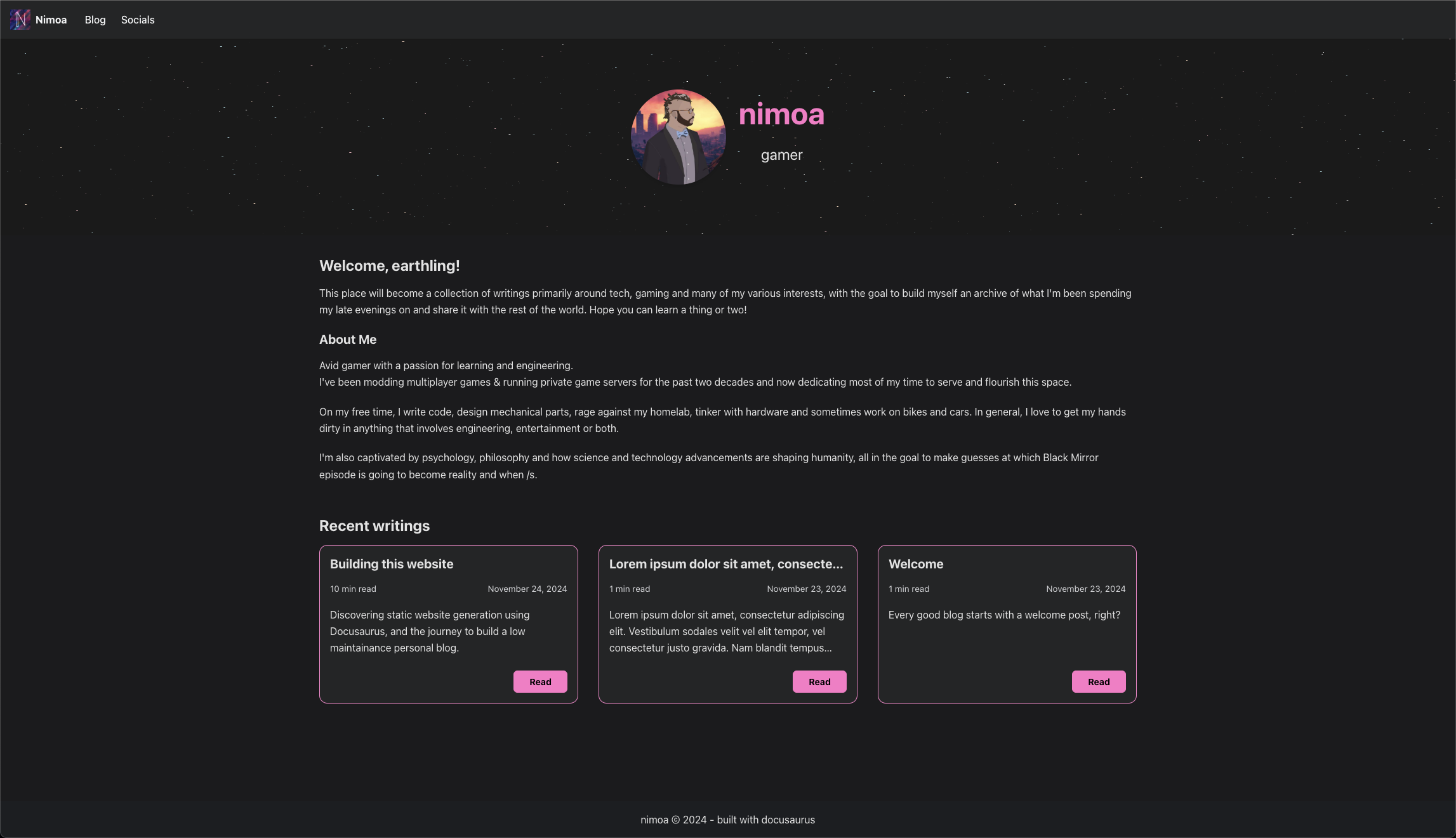
After:
I wanted to make it a bit more reactive, and to tone down the bright pink.
Openrouter and cloaked models
I started to explore a few visual improvements using Horizon Beta (I did not try Alpha, was too late!) following a few tweets I saw in my timeline that were praising the frontend capabilities of a new cloaked model available for testing on openrouter.ai.
It was a good opportunity to try Openrouter, I was especially curious about the multitude of inference providers they have and how a certain one named Cerebras is pushing mindblowing token per second figures, like the recent 120b open weight model from OpenAI running at 3000 token per second. 🤯
Quite an impressive speed! I need to explore more potential use-cases for extra fast reasoning models + these open models are a great advancement for locally ran LLMs & privacy, private models still offer compelling capabilities.
Using Horizon Beta
After Sonnet 3.7, Sonnet 4 has been my go-to model to use with Copilot's Agent mode in VScode thanks to the great tool calling capabilities of Anthropic models, allowing them to figure out which tools are relevant to use to accomplish a given task, and also proactively ensure the implementation is correct - which is surely impressive, especially when tool calling is used to verify what the agent just implemented and troubleshoot implementation issues.
Horizon Beta was capable of making good suggestions; the hue on top of the Hero particles was even one-shot by Horizon Beta without any errors but these models were not so good at debugging themselves through tool calling, so I was switching back and forth with Sonnet 4 to do troubleshooting and fix rendering issues.
I left the project on the side until...
OpenAI drops GPT5
Turns out, Horizon models were early checkpoints of GPT5, damn! I decided to continue the changes I started with Horizon Beta + Sonnet 4 with the release version of GPT5, which was now working fine with Copilot, and was showing great coding performance.
I added a progress bar that will now follow your progress through the length of the page you're currently reading:

And a handy scroll to top button will allow to quickly go back up.

With these two quality-of-life changes, a bunch more of minor styling adjustments to make the blog consistent with the homepage and a social page, I'm quite happy with the results.
I also forgot to mention it, but the homepage's "glitch/revealing" animation is where GenAI can shine for me. I described the effect I wanted, citing inspiration from Matrix, and in a few minutes, I was able to iterate on an effect and speed that was matching my desire.
To also reward those of you who will pay attention, try to type matrix on your keyboard while browsing the blog. :)
Social Cards
The last bit I was missing since the release are Social Cards, the embed/previews that show-up on social medias and messaging platforms.
Research phase
Like any sensible person would do, my first step was to open a search engine and research what already exists in the Docusaurus ecosystem to address the need for social cards generation. As you would expect from any mature open-source ecosystem with a large enough community, I was immediately able to find some interesting reading from Docusaurus's maintainer, Sébastien Lorber, directly on the Docusaurus Github repository: RFC: social cards #2968.
Open Graph protocol to the rescue
Reading through the rest of the comments made by the community on this issue, the name "Open Graph" was mentioned multiple times. As every social media platform started to implement their own way to process web pages metadata, Facebook/Meta decided to implement a standard which other companies/platforms can adopt as well when wanting to provide more information about a shared link: the Open Graph protocol.
In short, the protocol works by adding specific meta tags to the <head> section of HTML pages. These tags (like og:title, og:description, og:image, and og:url) provide structured information about the content that social media and messaging apps can read when a link is shared. The platform's crawler reads these meta tags and displays the specified image, title, and description instead of a plain text link - making the content more engaging and clickable.
Time to implement!
Over-engineering it, once again
Back in the mid 2000s, private MMORPG game servers were using forums to centralize and coordinate with their community of players. One of the ways you would differentiate from other servers was by ensuring your forums were personalized. While learning to include server stats on phpBB forum headers (online players, total characters and total currency), another idea that came to my mind was to allow players to show off their characters inside their signature. To do that, I did a lot of research on how I could create a php page that would render an image with data pulled from the server database about your character: name, guild, alliance, level, race, class & Adena (currency).
While I don't have at hand the php file I made back then (I really need to dive into my very old hard drives...), I used the imagick php library to dynamically print the data using a custom font on top of a background image template and expose that to an API endpoint.
The reason I'm mentioning this is because a cool feature that I've seen on a few blogs is embedding the article metadata inside the social card image instead of using a generic image identical regardless of the content of your page, and I knew immediately that I could replicate the approach I used in my glorious teenager php days, so I decided to go with it.
But because I haven't really done any php for the last 15 years (and I'm quite thankful for it!), and because through my research I discovered Sébastien documenting three different possibilities for implementing social cards here, here was what I started to explore:
- We could generate the cards as a build step, using a headless chromium instance in the CIs that support it
- We could host lambdas/server-less functions to generate the images "at the edge"
- We could use SaaS services like Cloudinary or similar
And while I first considered the build-time generation, since I use Gitlab & Cloudflare Pages integration, it wasn't the easy option. So...
Implementing dynamic generation with Cloudflare Workers
Since I use Cloudflare Pages to deploy and host this website in production, I could benefit from the direct integration with Cloudflare Workers through Pages Functions. I ended up implementing the image generation using Vercel's Satori library. Satori is pretty clever - it converts HTML and CSS (written as JSX/React components) directly to SVG.
With the help of GPT5, I created a serverless function to render the article metadata into a SVG file on-the-fly at the edge. This means each blog post can have its own unique social card image dynamically generated without storing any static files, and it's all served from Cloudflare's edge network alongside my blog.
And after some very minimal effort, here's how they look today on Twitter for my articles:
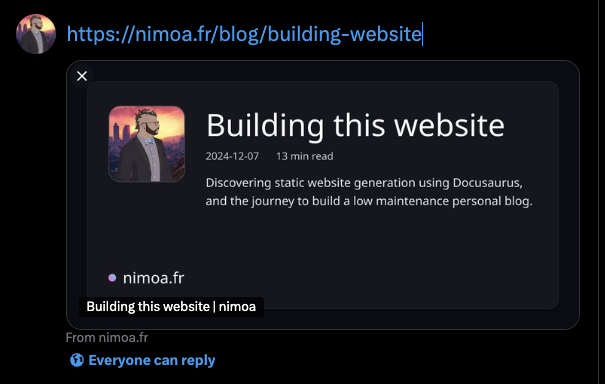
Pretty cool! And what's even cooler is that it's fully free since you get quite a lot of free compute time for Cloudflare Workers, so I don't even have to worry about that.
Conclusion
This blog and its evolution over the last year is a statement of how much more powerful AI models became at coding in that little amount of time. I've been able to speed up all my research & development projects using LLMs ever since ChatGPT launched, and while I have concerns that I hope to share in a later blog post, they are incredibly useful tools.
Hope this article can be useful to any human, and worst-case, it will become training data served to you as LLM tokens at a later point anyway.
